资源类型:UE插件
支持引擎版本:4.26 – 4.27 和 5.0 – 5.5
文件格式:持续更新
包含内容:插件
描述
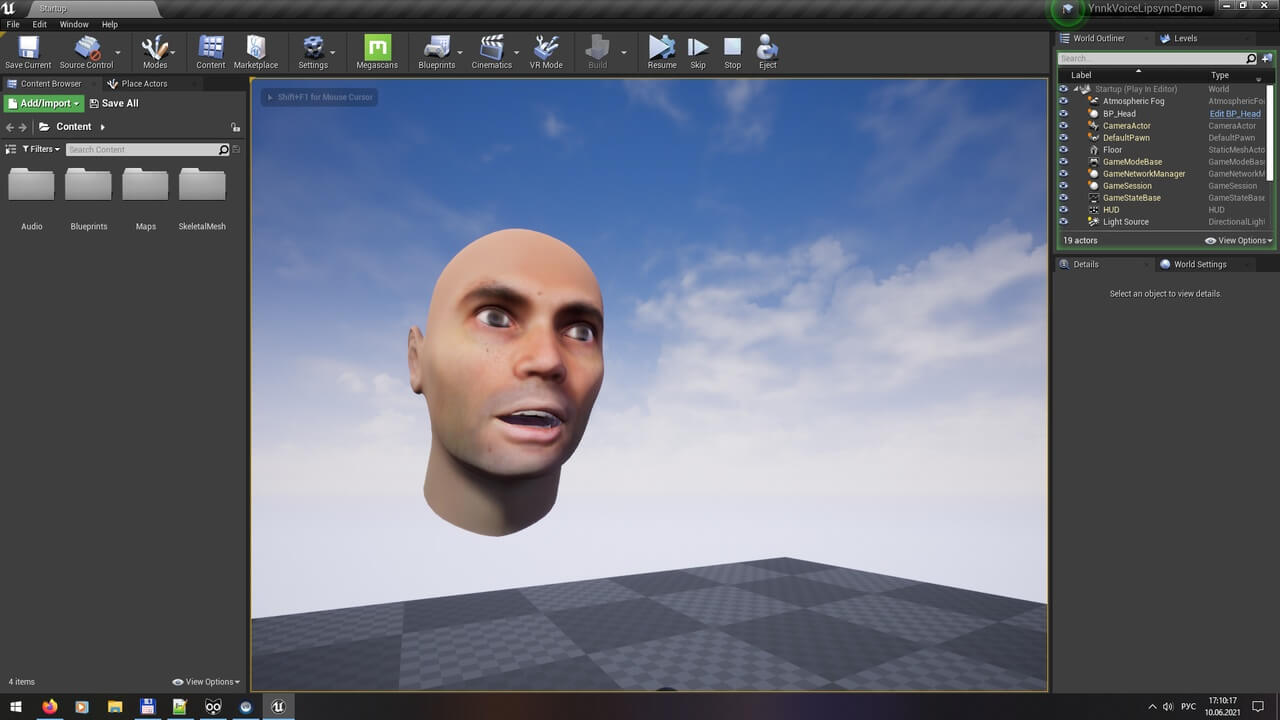
此插件使用语音识别引擎从 SoundWave 资源或 PCM 音频数据生成口型同步动画。动画以曲线形式保存在数据资源中,可在运行时与音频一起播放。这种方法可以轻松实现美观的口型同步动画,无需字幕。
附加功能:运行时识别来自麦克风的输入(语音转文本)。
MetaHuman 的新教程。
CC3/CC4 的新教程。
2 月 24 日更新说明:新的语言设置和包装流程
与文本转口型解决方案不同,这是真正的语音转口型插件。您不需要字幕即可制作出动画口型,并且生成的动画比基于字幕的解决方案更接近语音。
口型同步可以在运行时生成,但不能实时生成。也就是说,它不能与麦克风或其他流式音频配合使用。
全面支持以下语言:英语、中文。还支持:俄语、意大利语、德语、法语、西班牙语、葡萄牙语、波兰语。
Whisper 插件(使用 Whisper 代替 Vosk): YnnkWhisperRecognizer
要查找文档和演示项目,请单击下面的“查看详细信息”,然后单击“技术细节”。
技术细节
特征:
-
不需要字幕;
-
离线工作;
-
可以在 Windows 和 Android 上运行时生成口型同步;
-
可以在编辑器中生成具有口型同步的动画序列资源;
-
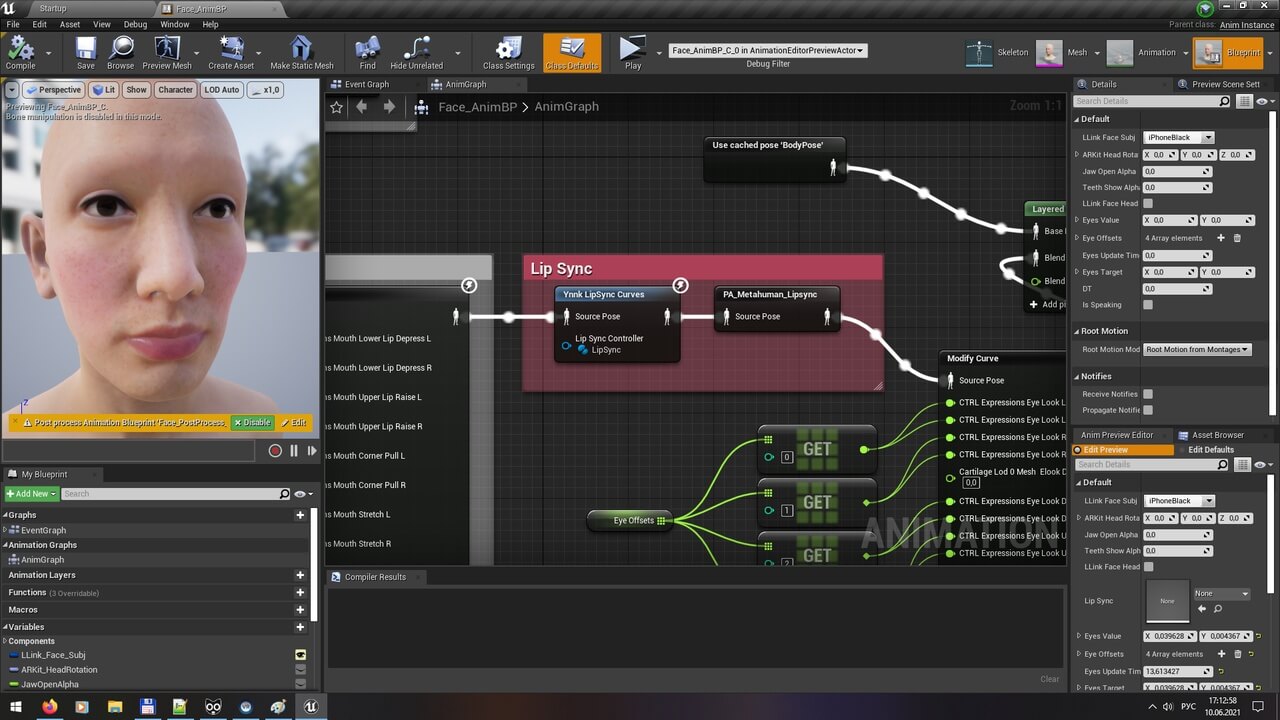
通过 Pose Asset(通用)和变形目标支持嘴唇动画;
-
异步音频识别和口型同步构建;
-
自动口型同步来自 11Labs TTS 的字符对齐数据;
-
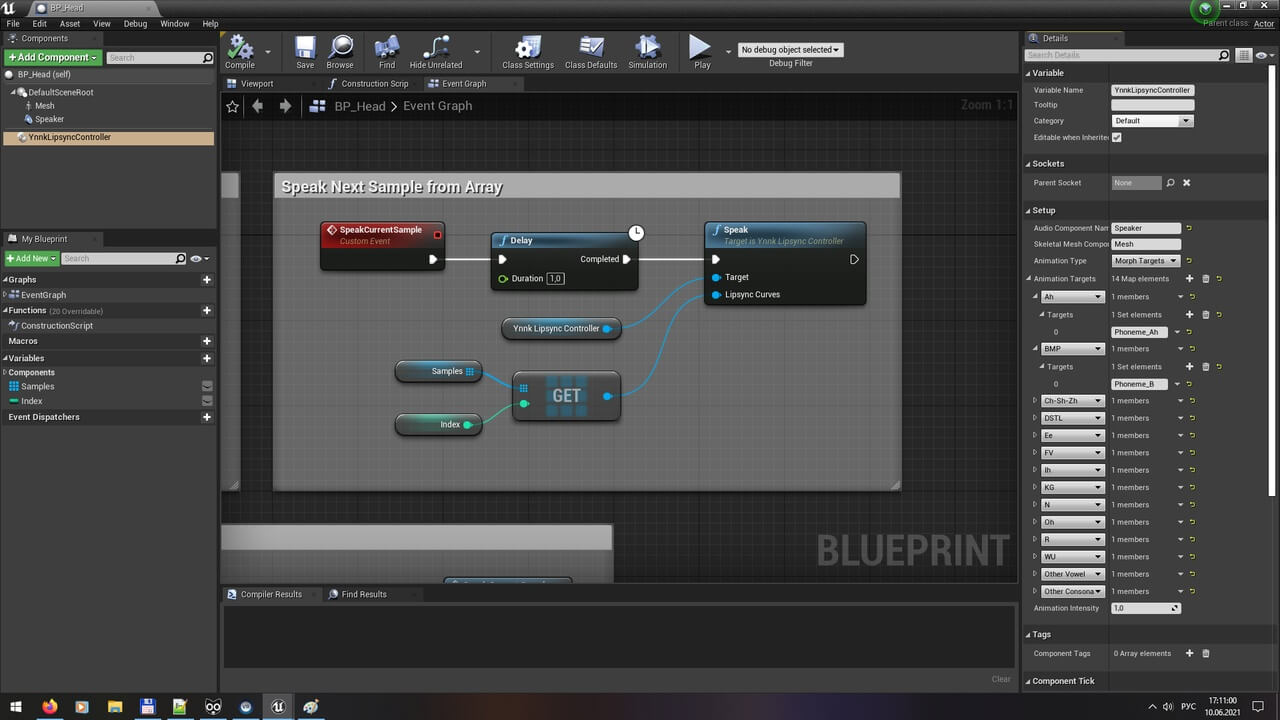
附加功能:运行时识别麦克风输入(语音转文本)(Windows、Android)。
代码模块:
-
YnnkVoiceLipsync(运行时)
-
YnnkVoiceLipsyncUncooked(仅未煮熟)
蓝图数量:0
C++ 类数:8
网络复制:否
支持的开发平台:Win64
支持的目标构建平台:Win64、Android
文档: Doc
示例项目: 5.5 | 5.2-5.4 | MetaHuman 5.5
可执行演示: ZIP


评论(0)